Tianyi Alex Qiu
Hi! I am Tianyi :)
[My Priorities] I build solutions to AI alignment, with a focus on how it uplifts human truth-seeking and moral progress - what I believe to be the most important problem of our time.
[My Toolbox] By training, I am a computer scientist, machine learning researcher/engineer, and statistician. By disposition, I am an avid experimentalist, but loves to dig deep into my findings in search for a generalizeable & falsifiable theory. As an AI alignment researcher, I also learn from economists (i) how to do reliable causal inference and (ii) how to think about multi-agent interactions. After all, both fields study complex systems (humans, AIs) embedded in larger complex systems (societies).
[My Impact] I care about deliverables and real-world impact above all else, and I'm excited that two of my open-source projects on at-scale LM alignment training (one, two) have, respectively, been downloaded by 20k people and liked by 5k since their release. They are based on various research projects I led or co-led, some of which received distinctions such as Best Paper Award (ACL'25), Best Paper Award (NeurIPS'24 Pluralistic Alignment Workshop), and Spotlight (NeurIPS'24).
[My Whereabouts] I am a Foresight Fellow on Intelligent Cooperation, based in London. I previously worked with the UC Berkeley Center for Human-Compatible AI, have been a member of the PKU Alignment Team, and was, until recently, an Anthropic Fellow working with the Alignment Science and Societal Impact teams. I mentor part-time for the Supervised Program for Alignment Research - please also feel free to cold-email me if you'd like informal collaboration. I am also seeking full-time research/engineering positions! Please check out my CV.
Selected Works
You may head for my Google Scholar profile to view my other works!
Project: Facilitate progress
Here are some silly xkcd-style comics on what we call the lock-in hypothesis.
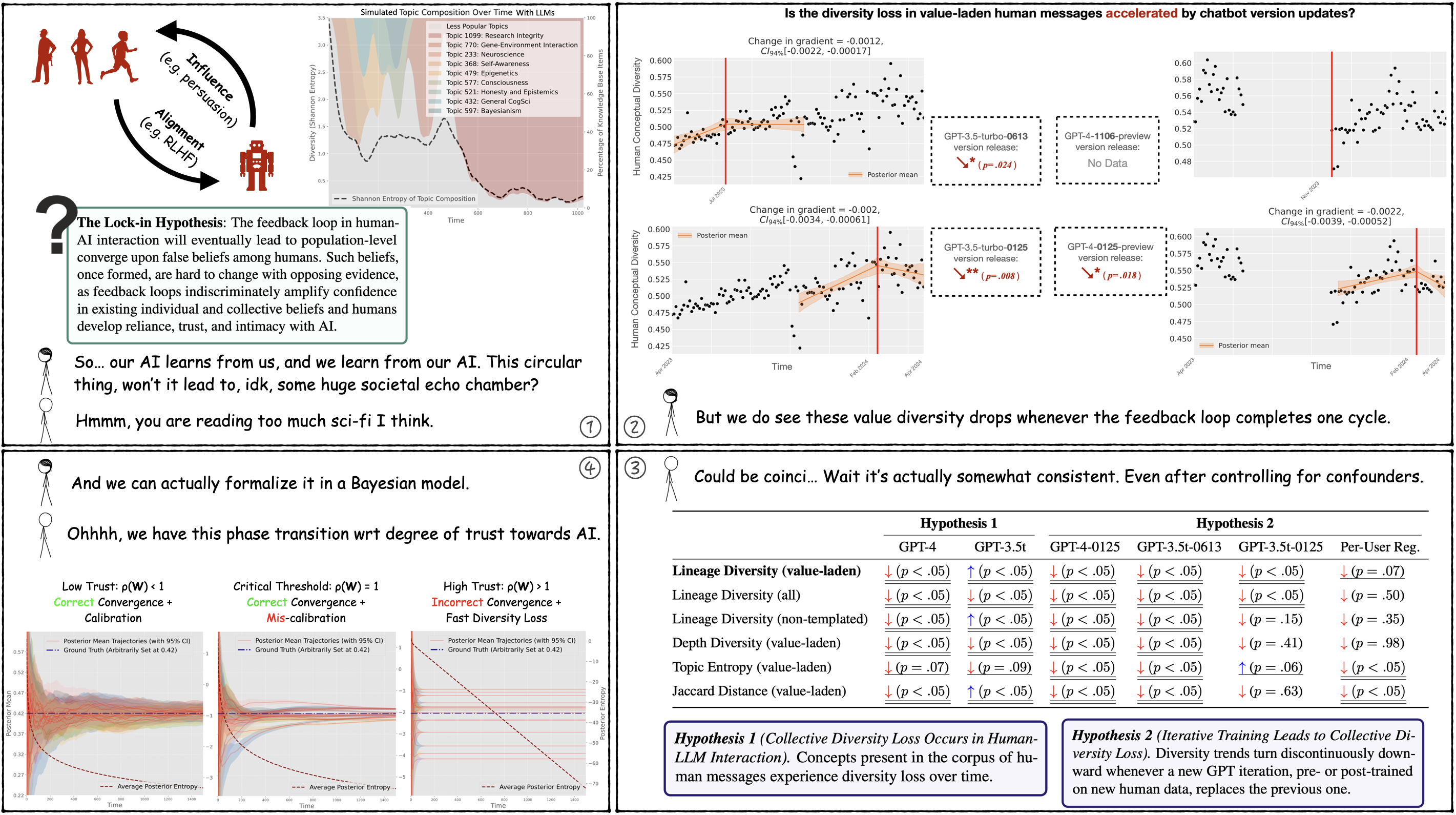
The Lock-in Hypothesis: Stagnation by Algorithm (ICML'25) Tianyi Qiu*, Zhonghao He*, Tejasveer Chugh, Max Kleiman-Weiner (2025) (*Equal contribution)
Danger (pre-mature value lock-in): Frontier AI systems hold increasing influence over the epistemology of human users. Such influence can reinforce prevailing societal values, potentially contributing to the lock-in of misguided moral beliefs and, consequently, the perpetuation of problematic moral practices on a broad scale.
Solution (progress alignment): We introduce progress alignment as a technical solution to mitigate the danger. Progress alignment algorithms learn to emulate the mechanics of human moral progress, thereby addressing the susceptibility of existing alignment methods to contemporary moral blindspots.
Infrastructure (ProgressGym): To empower research in progress alignment, we introduce ProgressGym, an experimental framework allowing the learning of moral progress mechanics from history, in order to facilitate future progress in real-world moral decisions. Leveraging 9 centuries of historical text and 18 historical LLMs that we trained, ProgressGym enables codification of real-world progress alignment challenges into concrete benchmarks. (Hugging Face, GitHub, Leaderboard)
ProgressGym: Alignment with a Millennium of Moral Progress (NeurIPS'24 Spotlight, Dataset & Benchmark Track)
Tianyi Qiu†*, Yang Zhang*, Xuchuan Huang, Jasmine Xinze Li, Jiaming Ji, Yaodong Yang (2024) (†Project lead, *Equal technical contribution)
We introduce the Martingale Score, an unsupervised metric based on Bayesian statistics, to show that reasoning in LLMs often leads to belief entrenchment rather than truth-seeking, and shows this score predicts ground-truth accuracy.
The key property we rely on: under rational belief updating, the expected value of future beliefs should remain equal to the current belief, i.e., belief updates are unpredictable from the current belief.
We think belief entrenchment is the major reason why LLMs are causing delusions and even psychosis in users today, and, if the root cause remains unaddressed, it may cause more serious epistemic harm at an even larger scale. Based on this work, we aim to extend the same metric to human-AI interaction, and to use it as a training remedy to belief entrenchment.
Stay True to the Evidence: Measuring Belief Entrenchment in Reasoning LLMs via the Martingale Property (NeurIPS'25)
Zhonghao He*, Tianyi Qiu*, Hirokazu Shirado, Maarten Sap (2025) (*Equal contribution)
Project: Theoretical deconfusion
Alignment training is easily undone with finetuning. Why so? This work proves, theoretically and experimentally, that further finetuning degrades alignment performance far faster than it degrades pretraining performance, due to the much smaller amount of alignment training data. We operate under a data compression model of multi-stage training.
Language Models Resist Alignment: Evidence From Data Compression (Best Paper Award, ACL'25 Main)
Jiaming Ji*, Kaile Wang*, Tianyi Qiu*, Boyuan Chen*, Jiayi Zhou*, Changye Li, Hantao Lou, Juntao Dai, Yunhuai Liu, Yaodong Yang (2024) (*Equal contribution)
Classical social choice theory assumes complete information over all preferences of all stakeholders. It's not true for AI alignment, nor for legislation, indirect elections, etc. Dropping such an assumption, this work designs the representative social choice formalism that models social choice decisions based on a mere finite sample of preferences. Its analytical tractability is established with statistical learning theory, while at the same time, Arrow-like impossibility theorems are proved.
Representative Social Choice: From Learning Theory to AI Alignment (Best Paper Award, NeurIPS'24 Pluralistic Alignment Workshop; in press at the Journal of Artificial Intelligence Research)
Tianyi Qiu (2024)
It is well known that classical generalization analysis doesn't work on deep neural nets without prohibitively strong assumptions. This work tries to develop an alternative: an empirically grounded model of reward generalization in RLHF that can derive formal generalization bounds while taking into account fine-grained information topologies.
Reward Generalization in RLHF: A Topological Perspective (ACL'25 Findings)
Tianyi Qiu†*, Fanzhi Zeng*, Jiaming Ji*, Dong Yan*, Kaile Wang, Jiayi Zhou, Han Yang, Juntao Dai, Xuehai Pan, Yaodong Yang (2025) (†Project lead, *Equal technical contribution)
Project: Surveying the AI safety & alignment field
Since early 2023 when the alignment field started to undergo rapid growth, there has not yet been a comprehensive review article surveying the field. We have thus conducted a review that aims to be as comprehensive as possible, all the while constructing a unified framework (the alignment cycle). We emphasize the alignment of both contemporary AI systems and more advanced systems that pose more serious risks. Since its publication, it has seen citation by important AI safety works from Dalrymple, Skalse, Bengio, Russell et al. and NIST, and has been featured in various high-profile venues in the US, China, and Singapore.
I co-led this project.
AI Alignment: A Contemporary Survey (ACM Computing Surveys)
Jiaming Ji*, Tianyi Qiu*, Boyuan Chen*, Jiayi Zhou*, Borong Zhang*, Hantao Lou, Kaile Wang, Yawen Duan, Zhonghao He, Jiayi Zhou, Zhaowei Zhang, Fanzhi Zeng, Kwan Yee Ng, Juntao Dai, Xuehai Pan, Aidan O'Gara, Yingshan Lei, Hua Xu, Brian Tse, Jie Fu, Stephen McAleer, Yaodong Yang, Yizhou Wang, Song-Chun Zhu, Yike Guo, Wen Gao (2025) (*Equal contribution)
Trajectory
Aug 2020: Won a gold medal in the Chinese National Olympiad in Informatics 2020
Mar 2021: Started as a visiting student at Peking University
Nov 2021: Started reading and thinking a lot about AI safety/alignment
Sep 2022: Officially started at Peking University, as a member of the Turing Class
May 2023: Started working with the PKU Alignment Group, advised by Prof. Yaodong Yang
Jun 2024: Started working with the Center for Human-Compatible AI, UC Berkeley, co-advised by Micah and Cam
Sep 2024: Started as an exchange student at University of California, via the UCEAP reciprocity program with PKU
Jun 2025: Started as an Anthropic AI Safety Fellow, working on frontier AI safety and alignment
Talks & Reports
[Talk] The Lock-in Hypothesis and Truth-Seeking AI (Jul 2025)
[Talk] Belief Entrenchment and How to Remove it (Jun 2025)
[Talk] The Lock-in Hypothesis: Stagnation by Algorithm (May 2025)
[Talk] Representative Social Choice: From Learning Theory to AI Alignment (Dec 2024)
[Talk] Value Alignment: History, Frontiers, and Open Problems (Jun 2024)
[Talk] ProgressGym: Alignment with a Millennium of Moral Progress (Jun 2024)
[Talk] Towards Moral Progress Algorithms Implementable in the Next GPT (May 2024)
Plus a few that are not (yet) public.
Get in touch!
Please feel free to reach out! If you are on the fence about getting in touch, consider yourself encouraged to do so :)
I can be reached at the email address qiutianyi.qty@gmail.com, or on Twitter via the handle @Tianyi_Alex_Qiu.